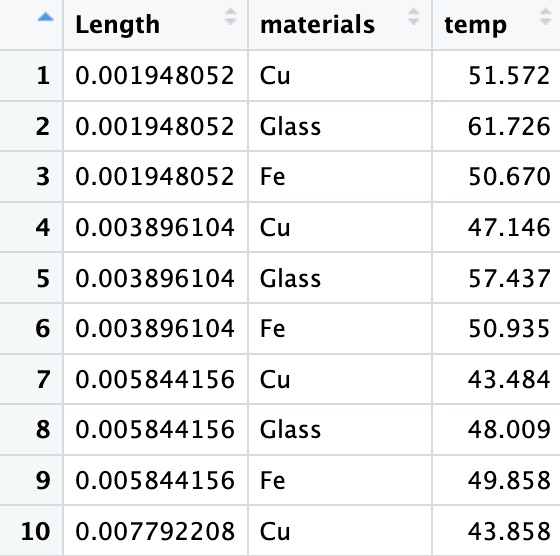
Authentication Code 방식 인증 프로세스 티스토리 API를 사용하려면 Authentication Code 방식을 통해 내가 API 사용에 적합한 사용자임을 인증해야 한다. 인증 프로세스는 다음과 같다. access token을 이용한 글 내용 요청은 인증에 성공하고 최종적으로 하려고 했던 프로세스이다. R에서는 이러한 인증 프로세스를 httr2 패키지로 진행할 수 있다. httr2 패키지는 R 필수 패키지인 tidyverse를 만든 해들리 위컴이 만들었다. 꽤나 최신 패키지라 그런지 httr2 패키지를 물어보면 gpt4가 이상한 응답을 내놓고 있다.(2023.10.27 기준) 때문에 이 글이 몇몇 소수의 R 덕후분들에게 가이드가 될 수 있지 않을까 살짝 기대해 본다. (httr2 패키지와 ..