1. Do you know tidy?
R을 사용하면 항상 사용하는 패키지인 tidyverse의 tidy에 대한 궁금함을 가져본 적은 없다.
하지만, <R을 활용한 데이터 과학>을 읽는 순간 tidyverse를 사용하기 전에 tidy라는 개념을 알아뒀다면 훨씬 수월하게 tidyverse를 사용했으리라 생각한다.(특히 ggplot2로 plotting 하는 속도가 달랐을 것이다.)

1.1. tidyverse
tidy + universe의 합성어로 이루어진 tidyverse는 R에서 가장 중요한 패키지(세트)라고 할 수 있다.
tidyverse에는 ggplot2, tibble, tidyr, dplyr 등 매우 중요한 패키지가 담겨 있다.
이중에서도 ggplot2는 차트, 그래프 등 여러 가지 데이터 시각화 요소를 깔끔하고 세련되게 만들어낸다.
엑셀로 만들어내는 그래픽과는 다른 전문적인 느낌을 준다.
ggplot2는 데이터 시각화에 관심이 있다면 반드시 알아둬야 할 라이브러리 중 하나일 정도로 강력한 기능을 갖고 있다.
ggplot2 뿐만 아니라 다음에 언급할 tidyr, dplyr 역시 데이터 전처리에 중요한 패키지다.
이 정도로 tidyverse는 R 생태계에서 큰 영향력을 갖고 있다.
1.2. tidy
tidy는 '정리된,깔끔한'을 의미한다.
데이터를 타이디하게 한다는 건, 데이터 셋을 일관된 형식으로 '깔끔하게' 저장한다는 것을 의미한다.
데이터를 가져온 후에는 정리하는(tidy, 깔끔한) 것이 좋다. 정리한다, 즉 타이디하게 한다는 것은 데이터셋이 의미하는 바와 저장된 방식이 일치하도록 일관된 형식으로 저장한다는 의미이다. - <R을 활용한 데이터 과학>
일관된 형식이란 무엇일까?
사실 너무나도 간단하고 당연한 형식을 해들리 위컴은 매우 강조하고 있다.
열 = 변수, 행 = 관측값
너무 당연하다는 생각이 들지 않는가?
당연히 데이터는 기본적으로 열은 변수, 행을 관측값으로 두는 걸 기본으로 하기 때문에, 별 거 아니라고 생각할 수 있다.
하지만 여기에는 상당한 오해가 있을 수 있다. 테스트해보자.
2. tidy data인지 판단할 수 있나요?
tidy data가 너무 당연하다고 생각하는 사람들에겐 먼저 반례를 보여주는 것이 좋다고 생각한다.
2.1. tidy 하지 않은 데이터 예시
head(TempC)TempC 데이터는 축방향 길이에 따른 여러 가지 재료의 막대 온도를 표시한 데이터다.
간단히 살펴보자.
길이가 길어질수록(즉, 0에서 멀어질수록) 모든 막대의 온도가 떨어지는 것을 확인할 수 있다.
Glass의 온도가 처음에는 가장 높지만, 마지막 10행을 보면 가장 낮은 것을 볼 수 있다.
자 그렇다면, 이 데이터는 tidy 한 데이터(타이디 데이터)라고 볼 수 있을까?
만약 이 데이터가 왜 타이디하지 않은지 설명할 수 없다면, 다음 내용을 쭉 읽어보는 편이 도움이 될 것이라 생각한다.
2.1.1. 열 = 변수, 행 = 관측값
타이디한 데이터는 '열 = 변수, 행 = 관측값'을 만족하는 데이터라고 했다.
TempC 데이터의 행을 먼저 살펴보자. 관측값이 맞는가?
그렇다. TempC 데이터의 행은 명확하게 관측값을 보여주고 있다.
그렇다면 TempC 데이터의 열은 변수가 맞는가?
여기서 문제가 생긴다.
우리는 문제를 정의하지 않고 그대로 데이터에 돌진하여 뜯어보려는 경우가 많다.
긴장을 풀고 문제부터 정의해 보자.
맨 처음에 나는 'TempC 데이터는 축방향 길이에 따른 여러 가지 재료의 막대 온도를 표시한 데이터이다.'라고 정의했다.
여기서 종속변수는 '막대 온도'일 것이고, 독립변수는 '축방향 길이', '막대의 재료'이다.
다시 TempC 데이터를 보자.

열에는 Length, Cu, Glass Fe가 있다. 이들은 변수가 맞을까?
Length는 '축방향 길이'다. 그러므로 변수가 맞다.
Cu, Glass, Fe는 어떠한가?
이들은 변수가 아니다. 이들은 변수의 값이다.
Cu, Glass, Fe의 변수는 '막대의 재료'다.
그리고 TempC의 열에는 종속변수 '막대 온도'도 없다.
때문에 이 데이터는 타이디한 데이터라고 할 수 없다.
2.2 long to wide! 피봇 하기(tidy data 예시)
이 타이디하지 않은 데이터를 타이디 데이터로 변환해 보자.
타이디하지 않은 데이터를 타이디 데이터로 변환하거나, 반대 방향으로 변환하는 것 모두 '피봇'이다.
TempC %>% pivot_longer(c(Cu:Fe), names_to = 'materials',values_to = 'temp') -> TempCtidy피봇 함수는 이름부터 pivot이다.
tidyr 패키지의 pivot_longer 함수를 사용했다.
gather함수를 사용하여 여전히 pivot 할 수 있으나, pivot_longer 함수로 대체되고 있다. 참고하자.

head(TempCtidy)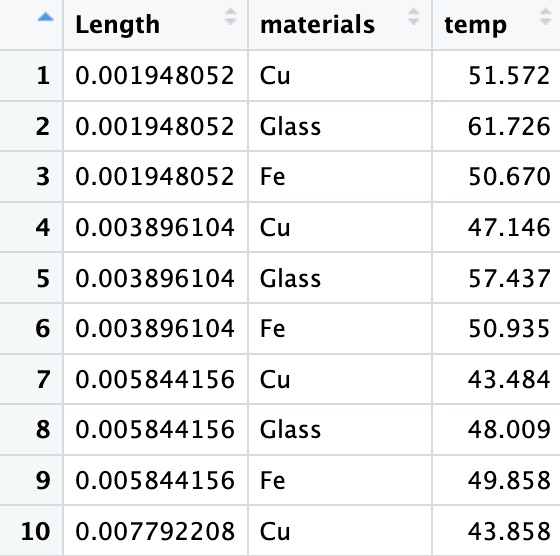
TempC와 TempCtidy를 비교하면서 둘의 차이를 명확하게 확인하길 바란다.
데이터를 타이디하게 만드는 것은 결국 문제를 제대로 정의해서 종속변수, 독립변수를 명확히 알고 있어야 가능하다.
특히, 헷갈리기 쉬운 변수값과 변수를 명확히 구분해 낼 줄 알아야 한다.
3. long data = tidy data
구글링하면 많은 경우 타이디 데이터를 long data라고 하며, 특이한 형태라고 생각하는 경우가 많다.
long data를 특이하게 생각하게 된 히스토리가 있겠지만, 내 생각에는 변수를 정확하게 정의하는 타이디 데이터야 말로 데이터 분석가가 보편적으로 지향하고 만들어내야 할 데이터 형식이 아닐까 싶다.
해들리 위컴은 <R을 활용한 데이터 과학>에서 long data라는 단어를 인정하지 않는 의견을 제시했다.
나는 데이터셋이 '긴 형식(long form)'이라고 표현하는 것이 맞지 않는다고 믿는다. 길이는 상대적인 용어이고, (예를 들어) 데이터셋 A가 데이터셋 B보다 더 길다고만 이야기할 수 있는 것이다. - <R을 활용한 데이터 과학>
tidyverse의 구성원 중 하나인 ggplot2 역시 기본적으로 tidy data를 지원하고 있다.
때문에 tidy data가 아닌 데이터를 사용하면 ggplot2를 사용하는데 상당한 어려움을 겪을 수 있다.
다음 글은 tidy data를 사용하지 않았을 때, ggplot2 적용에 어떤 문제점이 있는지 확인해 보겠다.
참고
<R을 활용한 데이터 과학, 해들리 위컴/개럿 그롤문드 저, 김설기/최혜민 역, 인사이트, 2019>
R을 활용한 데이터 과학 | 해들리 위컴 - 교보문고
R을 활용한 데이터 과학 |
product.kyobobook.co.kr