Foundation 모델의 탄생
다양한 문제를 푸는데 기반이 되는 AI모델, Foundation 모델(흔히 생성형 AI, Generative AI)이 등장한다.
모델? 파라미터?
모델(model) = 함수(function) = 프로그램(program) : 입력을 하면 출력이 나오는 형태.
AI 모델은 수많은 정답(데이터)에 가장 확률적으로 가까운 함수(y=ax+b)의 형태가 되도록 훈련된다.
데이터가 많고 각각의 데이터에 가까우려면 1차 함수보다 훨씬 복잡한 함수가 필요할 것이다.

1차 함수는
형태가 된다.
이 형태에서 a와 b를 파라미터(매개변수)라고 한다.
2차 함수는 아래와 같은 형태이다.
여기선 a, b, c가 파라미터다.
1차 함수에는 파라미터 2개, 2차 함수는 파라미터 3개...
이런 식으로 함수가 복잡할수록 파라미터는 점점 늘어난다.
(chatGPT는 1750억 개의 파라미터를 가지고 있다.
즉, (1750억-1)차 함수라는 것이다.
+어떤 AI모델이 ‘크다’, ‘거대하다’고 하면, 보통 파라미터의 개수가 많은 것.)
AI 모델은 사람이 만들어낼 수 없는 함수로 이뤄져 있기 때문에,
사람이 논리적으로 만들어낸 모델(기껏해야 3차 함수 정도) 보다 복잡한 데이터(정답)에 놀랍도록 가까운 답을 보여줄 수 있다.
다만, AI가 어떻게 더 좋은 정답을 가진 파라미터를 찾아낼 수 있는지에 대해서는 밝혀지지 않았다.
이는 수학적으로 증명되거나 원리가 확실히 밝혀진 부분은 아니다.
사전 학습 Pre-training은 어떻게 이루어지는가?
예전에는 개별 문제를 풀기 위한 AI 모델만 있었다.
(ex : 바둑 문제를 전문적으로 푸는 딥마인드의 알파고 같은 AI 모델.)
여러 가지 문제를 해결할 수 있는 범용 모델인 Foundation 모델을 만들기 위해서는 사전 학습(Pre-training)이 필요하다.
Pre-training을 거쳐 Foundation 모델을 만든 후,
이 모델을 이용하여 특정 문제를 더 적합하게
(더 정확하거나, 더 창의적이거나, 더 논리적이거나, 문제에 따라 다르다.)
해결하려면 Adaptaion(= Fine Tuning)이 필요하다.
과거와는 달리 AI의 학습 단계가 두 단계로 나뉘는데,
초거대 AI는 Pretraining에 집중한(어마어마하게 많은 Pre-training이 되어있는) Foundation 모델이다.
아래 그림과 같이 AI는 단어를 가리고 맞추는 학습을 한다.
이러한 학습을 많은 양의 데이터로 반복한다.
이것이 프리 트레이닝, 사전 학습이다.
왜 AI는 이전보다 똑똑해졌을까?
- 이전보다 훨씬 많은 학습 데이터를 사용했다.
- 예전에는 학습 데이터를 사람이 하나하나 보여주고 테스트하는 방법을 사용하여 많은 데이터를 학습시키기 어려웠다.
- 하지만 현재는 리워드 모델(Reward Model, RM)을 이용해 이러한 학습을 AI 스스로 할 수 있기 때문에 이전보다 훨씬 더 많은 데이터 학습이 가능해졌다.
- 이전보다 훨씬 큰 모델(파라미터가 많은 모델)을 사용했기 때문.
따라서 이렇게 많은 데이터를 학습한 거대한 AI 모델을 "초거대 AI"라고 한다.
초거대 AI는 앞서 밝힌
1. 엄청난 양의 데이터 학습과
2. 모델 크기 덕분에
적은 예시(Few-shot)를 보고도 그 예시(prompt)가 가진 맥락에 맞는 답을 우리에게 보여줄 수 있다.
하지만 맥락에 맞는 예시를 잘 제공할수록 AI는 더 좋은 답, 사람이 원하는 답을 제공할 수 있게 된다.
이 때문에 Prompt Engineer라는 직군도 생겨났다.
또한 예시가 없는 상황에서도 AI는 답을 제공할 수 있는데, 이를 "Zero-Shot"이라고 한다.
chatGPT는 법, 경영, 의료에 대해서는 배운 적이 없지만, 변호사 시험, CPA, MBA, 의사 면허 시험에도 통과할 만큼 똑똑하기도 하다.
AI는 거대해야만 똑똑할까?
모델을 엄청 크게 쌓고 많은 데이터를 사전학습시킨 초거대 AI.
2021년 딥마인드에서는 엄청나게 많은 매개변수를 가진 큰 모델이 자신의 능력을 충분히 잘 활용하고 있는지에 대해 의문을 제기한다.
모델 크기를 4분의 1로 줄이고 학습 데이터를 4배로 늘려 pre-training을 실시하여 성능을 비교해 보기로 한다.
이렇게 하면 이전과 동일한 컴퓨팅 파워(= 돈, 비용)를 투자하여 학습할 수 있다.
결과적으로, 크기가 작지만 학습 데이터가 많은 모델이 더 뛰어난 능력을 보여주었다.
모델의 크기가 작을수록 서비스 운용 비용은 감소한다.
이를 통해 더 많은 사람들이 다양한 분야에서 더 저렴하게 AI를 사용할 수 있게 될 것이다.
딥마인드의 시도를 통해 AI 모델을 더 최적화할 수 있는 여지가 있음을 알게 되었다.
작은 모델, 많은 학습 데이터
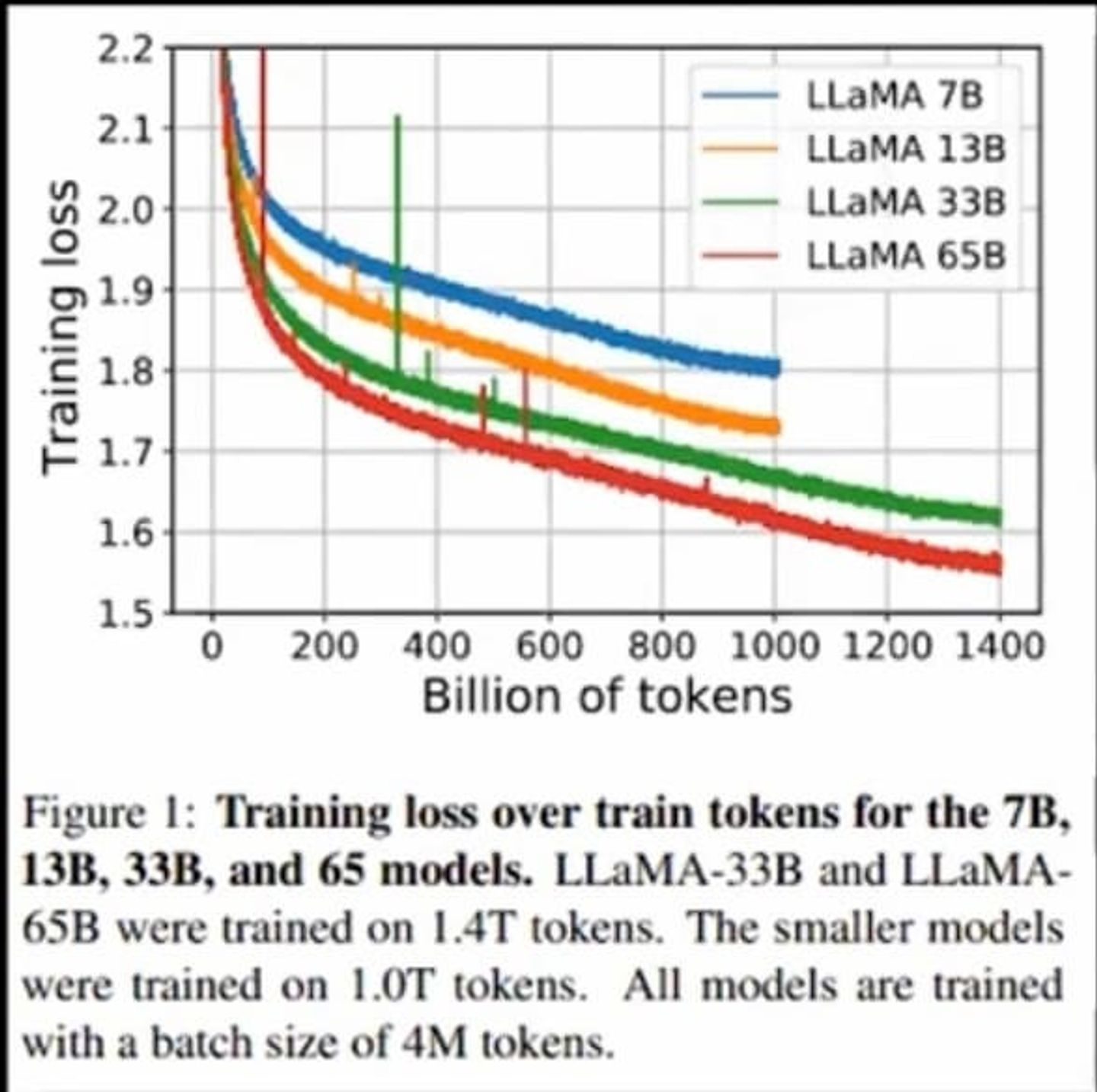
페이스북이 발표한 라마(LLAMA) 중 가장 큰 AI모델의 파라미터는 650억 정도다.
(chatGPT는 1750억 개의 파라미터.)
라마 AI는 chatGPT보다 작기 때문에 운용 비용도 적게 든다.
하지만, 라마 AI가 chatGPT보다 더 낮은 성능을 보이는 것은 아니다.
만약 라마 AI가 충분한 양의 데이터로 학습되었다면, chatGPT보다 더 뛰어난 성능을 발휘할 수 있다.
작은 모델과 많은 학습 데이터를 이용하여 효율적인 AI 모델을 만드는 방향으로 인공지능 기술이 최적화되고 있다.
참고